|
I am a second-year master student (MS in Robotics) at Robotics Institute, Carnegie Mellon University, advised by Prof. Jean Oh. Previously, I obtained my bachelor's degree from Yuanpei College 🦁, Peking University, majoring in Data Science (Computer Science + Statistics). During my undergraduate years, I was honored to be advised by Prof. He Wang. I was also previleged to work closely with Prof. Chuang Gan. I am always happy to chat and explore opportunities for collaboration. Feel free to reach out to me! I am seeking PhD positions starting in Fall 2026. If you have any suggestions or opportunities, please let me know! Email / CV (Dec. 2025) / Google Scholar / LinkedIn / Github / X (Twitter) |

|
|
My research lies in the intersection of Robotics and Machine Learning, with a focus on Robot Manipulation. My current research highlights the following perspectives:
Core research questions I am exploring:
|
|
(* indicates equal contribution.) |
|
Chengyang Zhao, Arxiv, 2025 [paper] [website] TL;DR: Modeling dynamic structures of complex deformable objects for model-based generalizable and adaptable manipulation. |
|
|
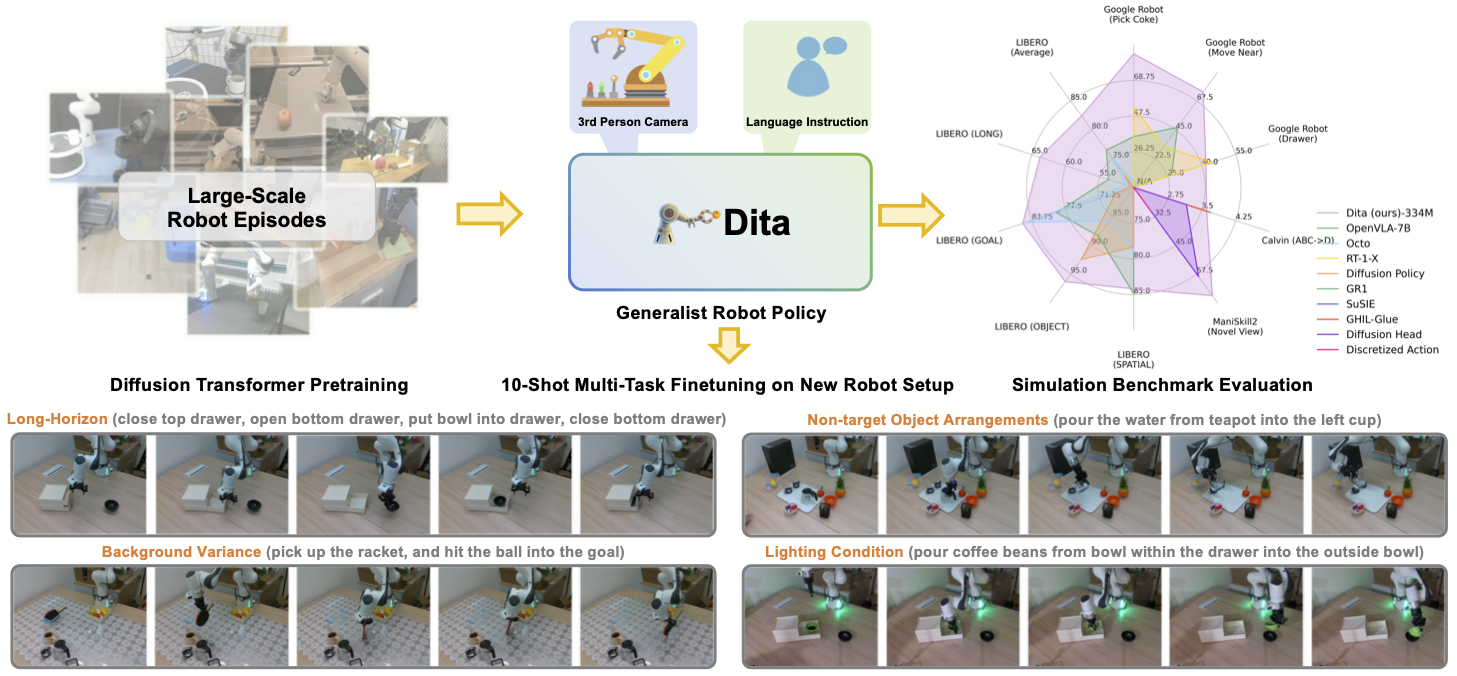
International Conference on Computer Vision (ICCV), 2025 [paper] [website] [code] TL;DR: A scalable DiT-based VLA policy with an in-context conditioning mechanism for inherent action denoising, enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. |

|
Robotics: Science and Systems (RSS), 2025 [paper] [website] [code] TL;DR: A unified infrastructure with simulator-agnostic interfaces to a wide range of simulators, aiming to enable universal configuration and hybrid simulation for scalable and generalizable robot learning. |
|
International Conference on Robotics & Automation (ICRA), 2025 [paper] [website] TL;DR: Robust depth perception for elementary functional structures and adaptable manipulation via online planning across potential interaction modes for articulated objects. |
|

|
Conference on Robot Learning (CoRL), 2024 [paper] [website] [code] TL;DR: Robust depth perception for daily rigid objects with challenging physical materials in tabletop manipulation scenarios. |

|
Chengyang Zhao, International Conference on Computer Vision (ICCV), 2023 [paper] [website] [code] TL;DR: Learning shared structured alignment across heterogeneous multi-modal data to build structured graph-based scene understanding capabilities. |
|
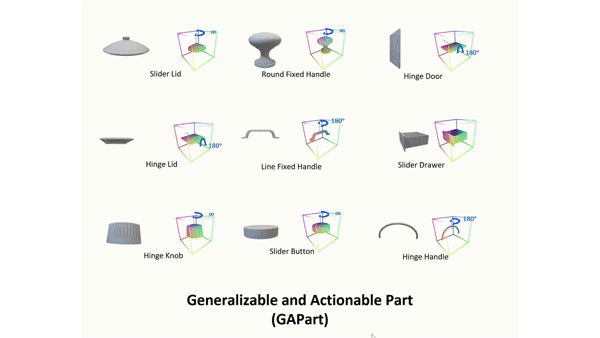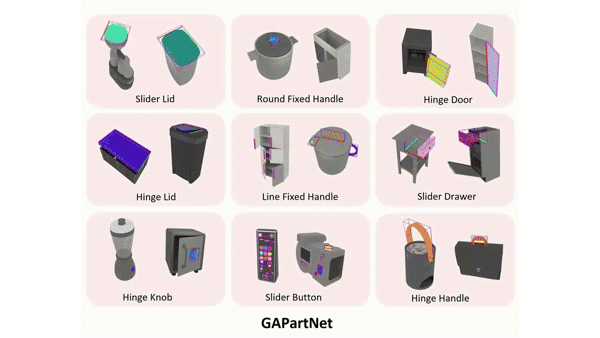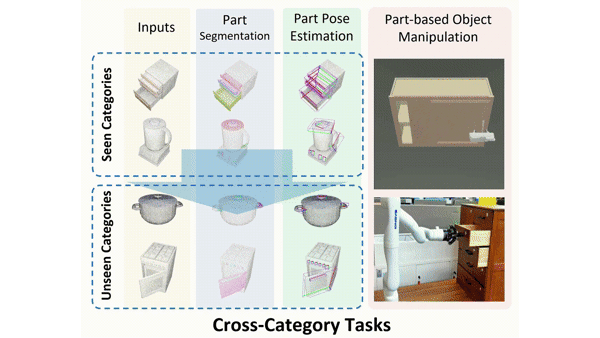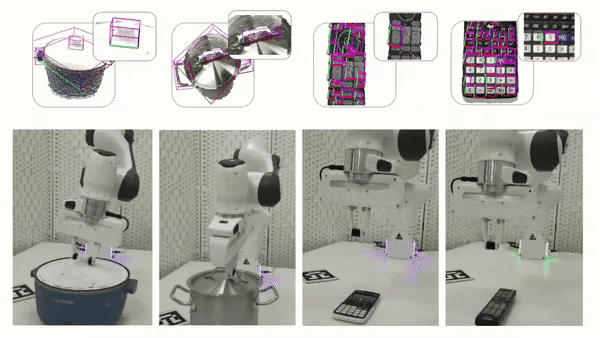
(* The order is determined by rolling dice.) Conference on Computer Vision and Pattern Recognition (CVPR), 2023 (Highlight) [paper] [website] [code] [dataset] TL;DR: Modeling shared elementary functional structures that remain geometrically consistent across various articulated object categories for generalizable perception and manipulation. |
|
Thanks Jon Barron for this amazing template :D
|